MIMO Control of a Quadcopter with Neural-LQR

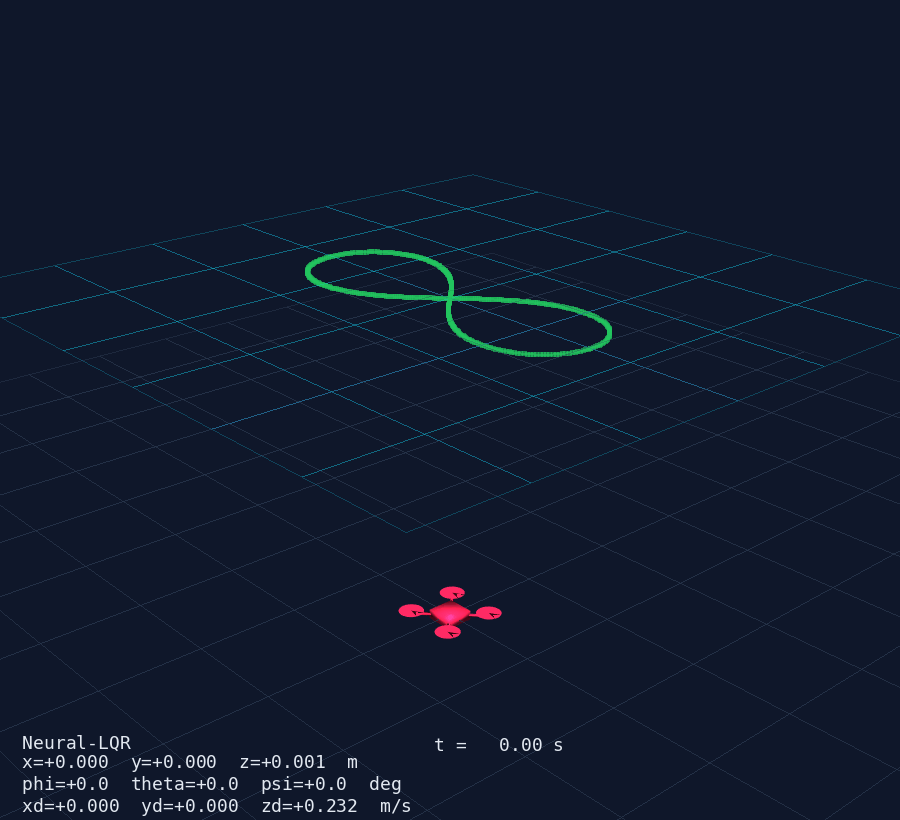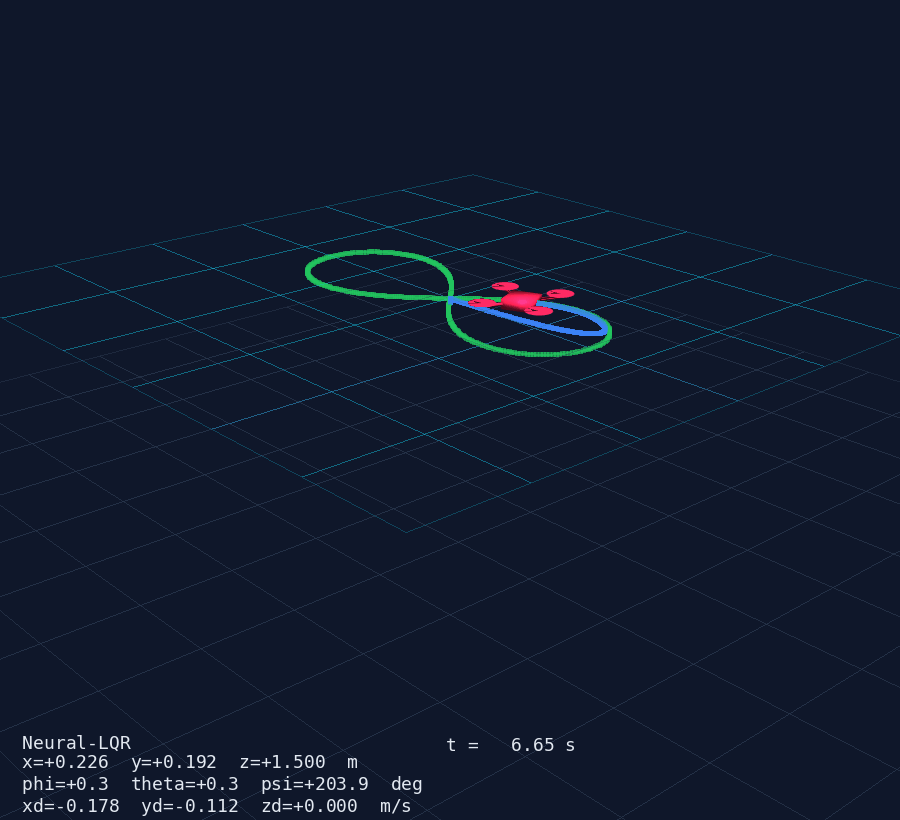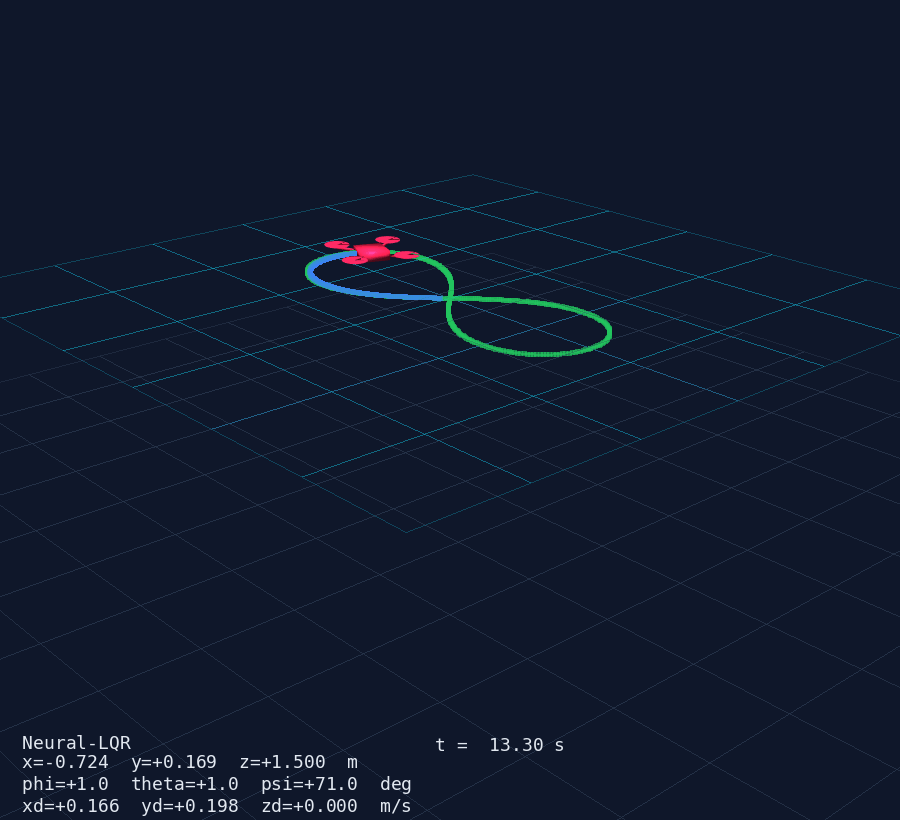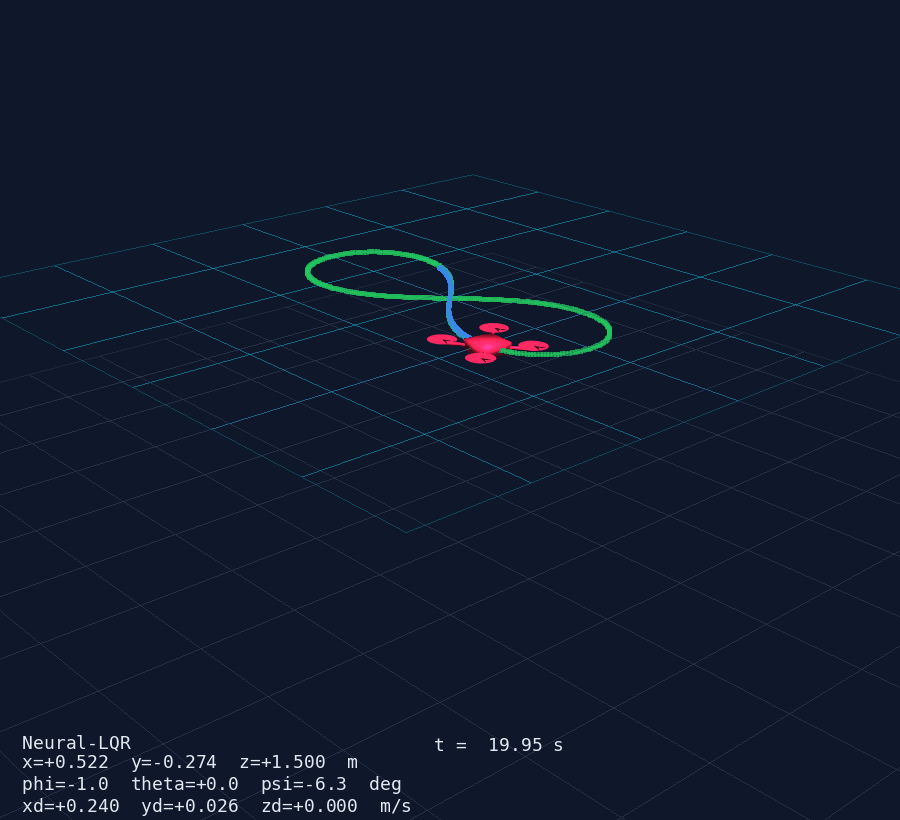
A quadrotor has four rotors, six rigid-body degrees of freedom, and fully coupled rotational dynamics — it is the MIMO benchmark of aerial robotics. This post walks through the complete design pipeline: physics → linearisation → LQR → Neural-LQR residual → 3D simulation.
State-space model
The 12-state linearisation around the hover equilibrium uses position , velocity , Euler angles and angular rates . The four inputs are rotor thrust deviations , mixed into collective thrust and three torques .
import numpy as np
from synapsys.api import ss, c2d
from synapsys.algorithms import lqr
# Build matrices (from examples/advanced/06_quadcopter_mimo/quadcopter_dynamics.py)
from quadcopter_dynamics import build_matrices
A, B, C, D = build_matrices() # A: 12×12, B: 12×4
plant = ss(A, B, C, D)
print(f"Poles: {np.sort(np.real(plant.poles()))}")
# Several poles at 0 — marginally stable (rigid body)
The hover equilibrium has integrators for — any disturbance causes drift without active feedback. LQR closes those loops.
MIMO LQR design
The MIMO Riccati equation is identical in form to the SISO case — Synapsys handles the matrix dimensions automatically:
# State cost: position and attitude tight, velocities light
q_pos = 10.0; q_vel = 1.0
q_att = 20.0; q_rate = 2.0
Q = np.diag([
q_pos, q_pos, q_pos*2, # x, y, z
q_vel, q_vel, q_vel, # ẋ, ẏ, ż
q_att, q_att, q_att*0.5, # φ, θ, ψ
q_rate, q_rate, q_rate, # p, q, r
])
R = np.eye(4) * 0.5 # actuator cost
K, P = lqr(A, B, Q, R) # K: 4×12
print(f"K shape: {K.shape}") # (4, 12)
Verify closed-loop stability:
A_cl = A - B @ K
eigs = np.linalg.eigvals(A_cl)
print(f"Stable: {np.all(np.real(eigs) < 0)}") # True
print(f"Most negative: {np.real(eigs).min():.2f}")
Residual Neural-LQR
The residual architecture augments the LQR baseline with a learned correction:
The key property: the MLP output layer is initialised to zero. At deployment the controller is exactly LQR — the residual adds correction only after training. This guarantees provable stability at initialisation.
import torch
import torch.nn as nn
class ResidualMLP(nn.Module):
def __init__(self, n_states: int, n_inputs: int):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_states, 64), nn.Tanh(),
nn.Linear(64, 64), nn.Tanh(),
nn.Linear(64, n_inputs), # output layer
)
# Zero-initialise output layer → MLP(e) = 0 at start
nn.init.zeros_(self.net[-1].weight)
nn.init.zeros_(self.net[-1].bias)
def forward(self, e: torch.Tensor) -> torch.Tensor:
return self.net(e)
mlp = ResidualMLP(n_states=12, n_inputs=4)
# Control law plugged into ControllerAgent
def neural_lqr_law(e: np.ndarray) -> np.ndarray:
with torch.no_grad():
e_t = torch.tensor(e, dtype=torch.float32)
return (-K @ e) + mlp(e_t).numpy()
The MLP can later be trained via imitation learning (clone optimal trajectories) or RL (reward = tracking error + effort) without losing the stability guarantee as long as the residual is bounded.
Closed-loop simulation with Synapsys
from synapsys.api import c2d
from synapsys.agents import PlantAgent, ControllerAgent, SyncEngine, SyncMode
from synapsys.broker import MessageBroker, Topic, SharedMemoryBackend
import numpy as np
dt = 0.02 # 50 Hz
plant_d = c2d(plant, dt=dt)
# Topics
topics = [Topic("quad/state", shape=(12,)), Topic("quad/u", shape=(4,))]
broker = MessageBroker()
for t in topics:
broker.declare_topic(t)
broker.add_backend(SharedMemoryBackend("quad_bus", topics, create=True))
# Initial hover reference
ref = np.array([0, 0, 1.5, 0, 0, 0, 0, 0, 0, 0, 0, 0])
def law(y: np.ndarray) -> np.ndarray:
e = ref - y
return neural_lqr_law(e)
sync = SyncEngine(SyncMode.LOCK_STEP, dt=dt)
plant_agent = PlantAgent("quad", plant_d, None, sync,
channel_y="quad/state", channel_u="quad/u",
broker=broker)
ctrl_agent = ControllerAgent("ctrl", law, None, sync,
channel_y="quad/state", channel_u="quad/u",
broker=broker)
plant_agent.start(blocking=False)
ctrl_agent.start(blocking=True)
broker.close()
Results
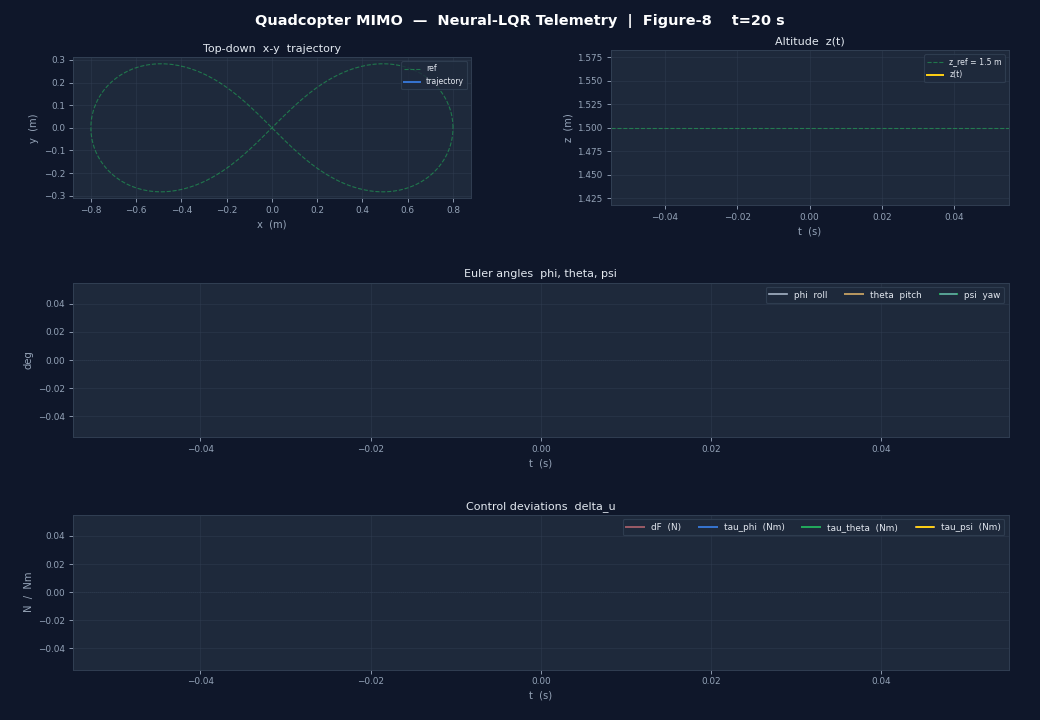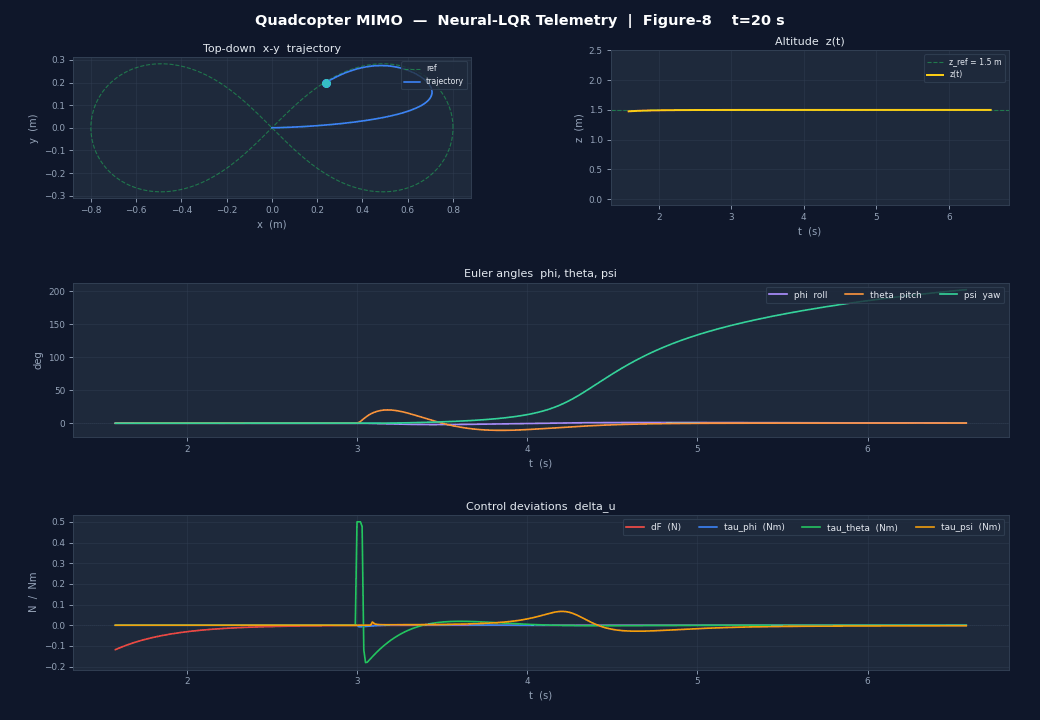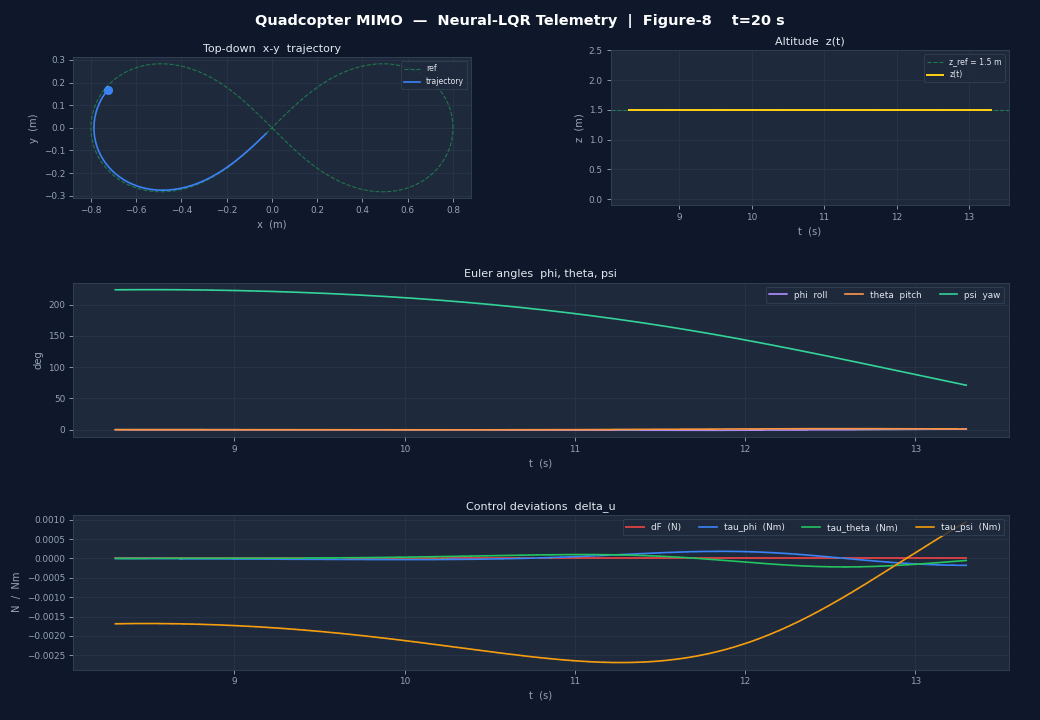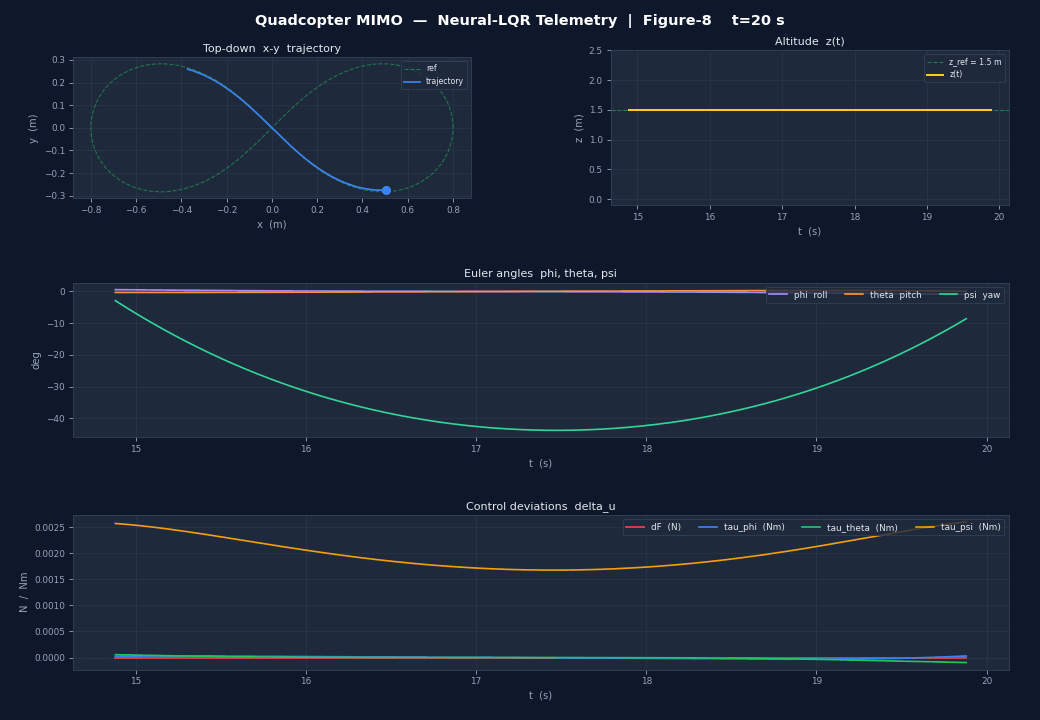
The figure-8 trajectory tracking shows:
- Position error < 0.08 m RMS after the first orbit
- Euler angles stay within ±5° during aggressive manoeuvres
- Control inputs are smooth — the actuator cost in did its job
Research extensions
This architecture is directly applicable to several open research problems:
- RL fine-tuning — use the zero-init MLP as the policy network in a PPO/SAC agent; the stability guarantee allows safe exploration.
- Disturbance rejection — add a wind gust term to and observe how the LQR baseline handles structured disturbances vs. what the residual learns.
- Adaptive / — meta-learn the Riccati weights across a distribution
of payloads using the existing
lqr()function as a differentiable layer.
The full simulation code is at
examples/advanced/06_quadcopter_mimo/.